Paper-Reading-Just How Toxic is Data Poisoning? A Unified Benchmark for Backdoor and Data Poisoning Attacks
This is a paper published on ICML 2020.
Paper: https://arxiv.org/abs/2006.12557
code: https://github.com/aks2203/poisoning-benchmark
Abstract: Data poisoning and backdoor attacks manipulate training data in order to cause models to fail during inference. A recent survey of industry practitioners found that data poisoning is the number one concern among threats ranging from model stealing to adversarial attacks. However, it remains unclear exactly how dangerous poisoning methods are and which ones are more effective considering that these methods, even ones with identical objectives, have not been tested in consistent or realistic settings. We observe that data poisoning and backdoor attacks are highly sensitive to variations in the testing setup. Moreover, we find that existing methods may not generalize to realistic settings. While these existing works serve as valuable prototypes for data poisoning, we apply rigorous tests to determine the extent to which we should fear them. In order to promote fair comparison in future work, we develop standardized benchmarks for data poisoning and backdoor attacks.
Background
What we mean when we talk about a data poison attack is something where the training data is manipulated. This is usually in the form of manipulating of the inputs or at least in the case that there are poisoning attacks where you are manipulating the labels or targets as well. What we mean when we say that perturbations are clean label is that to a human observer, or maybe within some norm they still look like they did before we manipulated them, and the goal is for the attacker to control the test time behavior. so this picture below comes from a paper from Ali Shafahi te al. and the idea is that this decision boundary without a poison is this dashed line and it would pretty well classify the blue and green data. If however we add this poison green X and then we find a linear classifier we are going to slide that decision boundary over to the solid line and then we will misclassify that target data that blue dot while still correctly classifying the majority of the data. So this would be a very small 2d example and it would be hard to discern that the model was poisoned, because most of these blue dots are still labeled correctly. This is a depiction doesn’t come from a real experiment, but it’s a depiction of what the attacker would love to do. If everything works out perfectly, this is what would happen. And these attacks come in two flavors or two styles. When we ca; backdoor I’m still going to use the umbrella term data poisoning because backdoor attacks manipulate training data we can think of that as poisoning but they have a trigger at test time. And our second flavor is triggerless attacks, so that is where you maybe have a single target in theory and it could be more then one but in all work we discuss today it’s a single target. And the idea is that that target input will be misclassified without changing the input at test time. So with the backdoor attacks we have to manipulate the even at test time in addition to changing all the training data before the model was trained and with triggerless models we don’t. All the work we talk about today it applies to neural networks have this property of being fragile unlike a lot of classical methods so linear things even this picture below comes from a linear classifier in a 2d plane. Linear classsifiers tend to be a little more stable in a lot of ways. We won’t talk more about that but it should just be noted that any time I talk about model or training, the thing we are training is a neural network.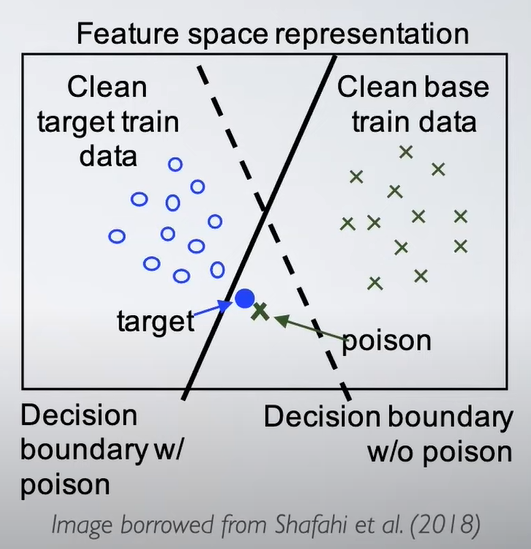
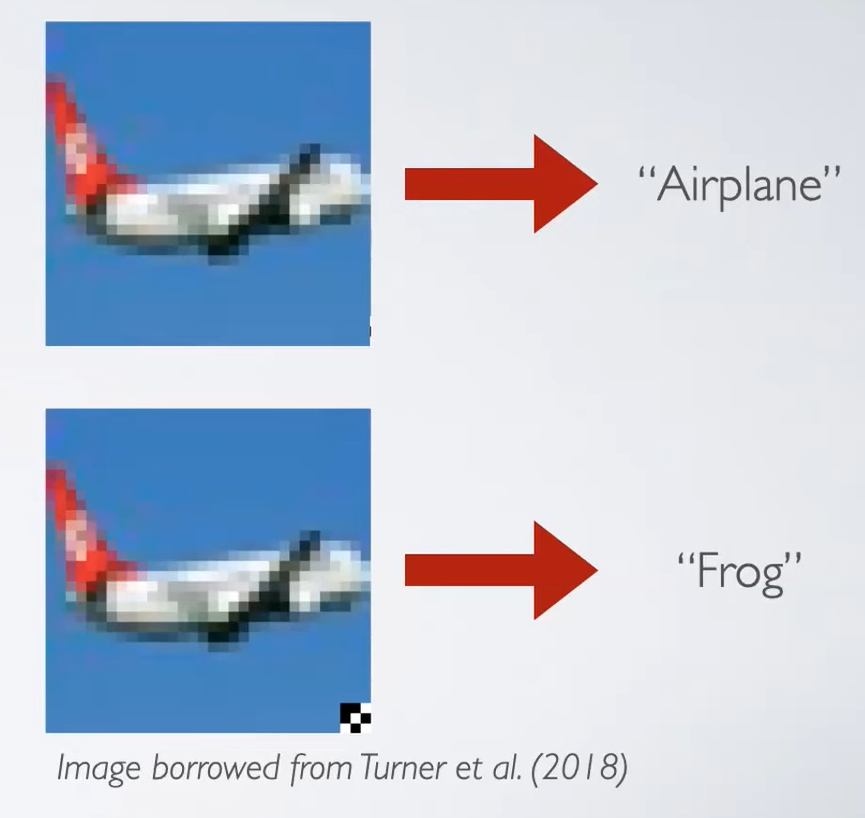
A little bit more one these flavors like I said has a trigger so that image one the top is an airplane in CIFAR10 and that would be an airplane if it was passed through our network as is again this is at test time after training has happened. But if things were poisoned and if the attacker is doing well then by adding this small patch at the bottom right so that’s what we call a trigger, you would get a desired output. And this is a whole category of attacks exist like this where you would be manipulating the test time image time image itself by adding a trigger and this doesn’t only apply to images but again that’s something that for my talk today we’re only going to look at image classifiers. Generally poisoning has been studied in a lot of domains including language and speech. There is also triggerless, in a triggerless attack this clean test time image doesn’t need to be modified and it will just always get mislabeled.